


After 2.5 years at Dyno Therapeutics, I have left and joined Noetik, an SF-based ML-bio startup building foundation models of tumor microenvironments. The company is somewhat early stage, having raised a $40M Series A in August 2024, and hovering at just above 30 people. My role is a bit non-traditional, and will involve a mix of ML, writing, and perhaps other things as well. After all, the poster I most recently made had a mild Noetik theme! My first week just wrapped up, so this seems like a good time as any to write an essay about it all.
Here, I will explain some beliefs I’ve been developing over the past year about the ML-bio field, why Noetik is one of the only startups I’ve found who shares the same thoughts, and what the startup is creating. This is the first time I’ve picked a place to work based on an actually formalized economic + scientific worldview of the field I’m in, so I’m quite excited to share this!
If you’re curious about the work we’re doing or want to partner with us, please reach out to me at abhishaike.mahajan@noetik.ai or DM me on X!

But first, appreciation. Dyno was the first time I ever had a chance to really learn biology x ML, and I am eternally grateful to the company for very much taking a chance on me — someone who had never done that sort of work before. Some of the smartest people I’d ever met in my life currently work at or have previously worked at Dyno, and it’s a place I’d highly recommend to anybody else. Dyno is rare amongst ML-bio startups for having pretty clear product-market-fit and an actual product. Patients want their gene therapy delivered better, and Dyno has real capsids on the market that solve that problem.
But I’ve become somewhat restless. After some soul-searching, I have landed on Noetik for my personal bet for where the future of ML in biology will be the most interesting. But before explaining why, I should explain some of the beliefs I have about this field at large. It’s fine to disagree with these, but I don’t think any of them are, as of today, strictly disprovable.
First, scaling laws in biology clearly aren’t playing out the same way as they did in natural language.
Parameter counts and tokens-trained-on keep going up for protein language models, but there aren’t particularly interesting properties that emerge from such models. There is an even worse story being told for scRNA foundation models! In general, it seems like many biology foundation models made back in 2021-2022 are still decently competitive with models made today, which is a worrying place for the field to be in.
Now, I don’t think that the scale hypothesis is wrong, but rather that it is potentially being misapplied. Scale in biology may be irrelevant if you only do unimodality scaling. Maybe you only get benefits if you first scale on the modality axis! Perhaps collecting information from every layer of the biology data stack will be necessary for anything transformative; biology is not as leaky as we wish it was, and you get very little ‘for free’ if you focus on collecting, e.g. only genomic sequences or only proteins or so on.
I have no idea if this is actually true, but it feels true.
Second, too many bio-ML companies are focusing on a problem that has strong competition from wet-lab methods.
I think there are really two (viable) options when it comes to applying ML in biology. The first one is to use fully open-sourced models as part of your normal preclinical wet-lab process. As in, little-to-no ML development is done in-house, and you simply hope that the mild usage of commoditized ML will speed up your investigative work. The second one is to focus on a (useful) problem so obscenely difficult, so intractable through usual means, that hand-crafted ML may be the only real hope at making any progress. These are the only two modes of operation that make sense to me.
But a surprisingly high number of bio-ML startups fall into this weird third bucket where they are trying to do bespoke machine learning for a problem that could just as easily have been done by…..phage display or chemical library screening or running mouse model experiments. I can buy that this made much more sense in, like, 2022, less so now that so many great open source models are out there. Of course, if you truly believe in your heart of hearts that the open source model spigot will stop soon, sure, I can buy that running this type of company may eventually pay off. But I’m betting on the spigot continuing.
Finally, three, the space of interesting, clinically relevant biology operates on much larger scales than individual biomolecules.
I think this is the most disagreeable thing I’ll say here, because it’s roughly the same thesis as systems biology as a field (though I admit this is somewhat an abuse of terminology). And systems biology hasn’t done particularly well. Nobody in the life-sciences will deny that biology is quite complicated, but, in the search for better drugs, the systems biologists have demanded that this complexity must be grappled with. This is all while most others have ignored it and have instead focused on far simpler questions, like ‘do we observe binding between this small molecule and this receptor?’. Here, the systems biologists have been left with egg on their face; many papers published, but few practical contributions to the very hard problem of pushing a drug to market.
If we trust historical precedent, we should also trust the pure protein foundation model folks to deliver upon us better and better drugs, since they are a rejection of what seems like a failed paradigm. This may work! But some part of me is deeply skeptical of the whole approach, at least if we trust that therapies will get increasingly complex, requiring a far broader awareness of biology than a single biomolecule. Systems biology may remain too broad of a brush, but we may still need something higher level than individual biomolecules.
Noetik is the one of the very few AI-biotech I’ve found whose revealed preferences for R&D matches up with these three beliefs that I have.
For the first point, their data collection is heavy at the modality level.
Data is collected across four areas: exome sequencing, H&E, spatial transcriptomics1 (read the footnote!), and immunofluorescence across 16~ proteins, the last three of which are derived from human tumor biopsies. For context, most companies working in the same space as Noetik are primarily collecting a very different type of data: single-cell RNA readouts within in-vitro cell lines. That sort of data is a lot cheaper + faster to collect, but an order of magnitude less information-rich. This may be helpful for some therapeutic areas, but, on average, I’d bet on data quality over quantity.
Currently, Noetik has this data for over 40 million cells across 2,500 patients — which represents the largest multimodal, paired dataset of its kind in the world — and is growing every month. And, recently, we are collecting in-vivo tumor perturbational data in mice as well.
For the second, they have focused on what is one of the hardest drug development problems in the world: cancer therapeutics.
To take the example of immunotherapy: when immunotherapy works for tumors, it is miraculous. Basically every case of spontaneous cancer reversal has been the result of ‘natural’ immunotherapy; instances where the body's own immune system unexpectedly recognizes and eliminates cancer cells. It was under that observation that led to the first case of artificial immunotherapy, in hopes of replicating this natural success: Coley’s Toxins.
Nowadays, we have an expanding and increasingly sophisticated arsenal of tools to do exactly this: checkpoint inhibitors, chimeric cell therapies, bispecific engagers, and so on. But immunotherapy doesn’t work for the majority of patients, and it is unclear why. We know that some tumors are “cold”, devoid of meaningful immune infiltration from the outset, while others are simply "immune-excluded," where T cells circle the tumor periphery but fail to penetrate. In still others, even when T cells are present, they are exhausted, suppressed, or disarmed by tumor-intrinsic resistance mechanisms. But even this do not explain all the variation we see in immunotherapy responses.
Are there purely wet lab ways to study this? Not if you suspect that many immunotherapy failures/successes are subtle, spatially distributed, and heterogenous across thousands of tumors. As such, ML may be an excellent tool to throw at the problem, since there’s really nothing else we can throw at it. There’s also some reason to suspect that immunotherapy as a field will grow, given that CAR-T therapy may see massive cost drops in the near future (see: Umoja).
This all said: what Noetik is building transfers quite well to basically any cancer drug outside of immunotherapy as well, immunotherapy is just a good case study.
For the final third point, Noetik, as is the case with every phenomics company, is implicitly placing a bet on bigger-picture understandings of biology being important.
I can’t prove that this is important, or even necessary. It just seems like it should be if we go down the route of increasingly complex drugs that interact with many [things] instead of a singular receptor, but I think it’s tough to predict the future. The most successful drug of the 2020’s has been Ozempic and Ozempic-follow-ups, none of which worked in particularly crazy ways. So who knows? I think it will be the case that while perhaps Noetik’s approach will be necessary for some therapies, there is so much steam left in simpler therapeutics that this point doesn’t really matter. Interesting places to join are always going to be based on bets on the future, not certainties. I know what I’m betting on!
So, what has Noetik actually built?
Their first public release was a self-supervised model called Octo-VC, which was pretrained on the aforementioned 4 modalities of data. From the release:
OCTO incorporates spatially-aligned, multimodal data from different tumor regions into a unified representation. To achieve this, we encode different data types in ways that best preserve their biologically relevant features. For example, multiplex fluorescence images, which measure protein expression in cells, are first split into color channels that represent discrete proteins and then “patchified” into individual tokens. Spatial gene expression data is modeled with one token per gene at each location that contains a cell. Once processed, the tokens are combined into a single sequence so that the model can reason across modalities and learn latent relationships between the underlying biology they represent. OCTO was pre-trained on 20B tokens across 128 GPUs and is able to include up to 16,000 tokens in its “context window” at inference time.
Here’s a helpful graphic describing the input data:
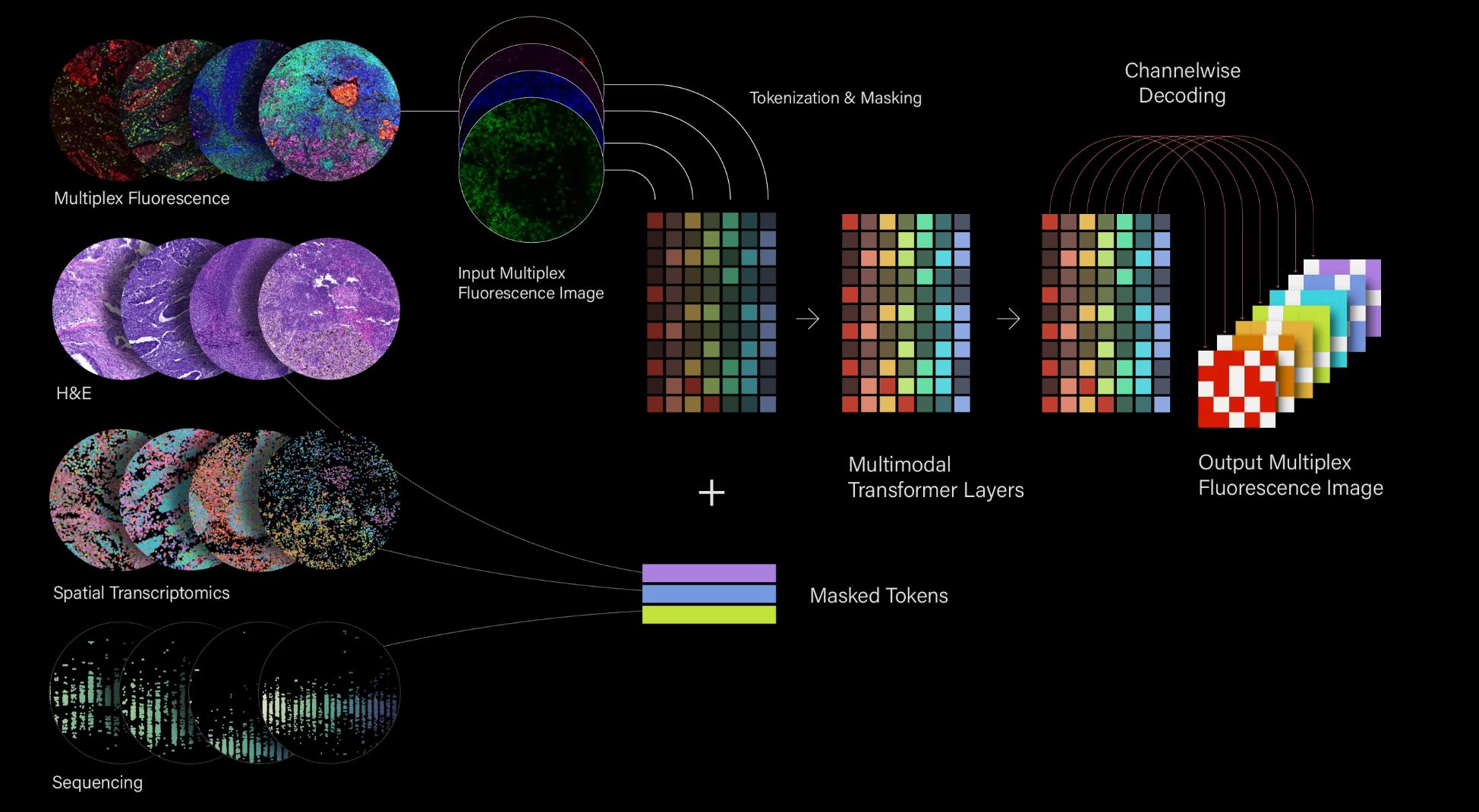
And empirically, doing this paired learning has allowed the model to learn something that is generalizable across biology. It’s been established by Noetik that the model can distinguish cell type purely from nuclei morphology, infer that certain T-cells co-express certain proteins, and other basic sanity checks — all without being explicitly trained on any of those.
In many ways, you could view this model as a ‘virtual cell’. This concept is not something that Noetik came up with and has, very understandably, become somewhat of a meme — a very expensive way to create something that seems impressive, but seemingly has little practical clinical value. I empathize with this worldview! But I am increasingly coming around to the idea that virtual cells are a useful abstraction for this sort of work. But if the phrase sounds uncomfortable, you could simply view Noetik’s work as creating a ‘foundation model of tumor microenvironments’ as I have. Here’s a fun released demo of Octo-VC!
Still, however you define it, the elephant in the room remains: what is the clinical value of something like this?
On a very basic level, you could ignore the virtual cell aspect of it all and simply use the model as a way to embed information about a patients tumor state. There is good internal evidence to suggest that the latent embedding produced by Octo-VC, given the aforementioned modalities, is more discriminative of who will and will not respond to certain immunotherapies than the current gold-standard (checking if a single biomarker, PD-L1, is elevated in tumors). This laid the foundations for one of Noetik’s first partnerships, announced just two weeks back, which is working on patient stratification for a combo immunotherapy.
But an even more ambitious way to view the system is as a counterfactual engine, allowing one to artificially perturb the proteomic, transcriptomic, or genomic inputs that has been given to model the potential impact of it on every other modality. For example, Noetik studied how increasing the transcriptional value of one gene affects a separate protein. Specifically, they varied the input value of IFNg — a protein secreted by T cells — transcription to observe the associated effect on HLA protein — a protein that a cell uses to display its internal state to immune cells. It is known from the literature that increased levels of IFNg should force increased HLA levels in tumor cells. And indeed, this relationship was mirrored by the model:

They also found that the models inference of the HLA protein itself followed spatial patterns:
There are also hints that OCTO has learned more subtle biology. Small simulated increases in IFNg signaling raise HLA levels at the tumor border but decrease them in the interior – a spatial pattern that we began to notice in many patients after seeing these predictions. This shows how simulation with a world model can reveal structure in the data that would be hard to detect in aggregate analysis.
One hope is that this model is useful for understanding new rules of spatial tumor biology, ones that allow us to learn about new cancer targets, why certain drugs fail, and how to make better ones. The combination of having true, in-vivo data and spatial context of that data may lead to a model that can teach us genuinely novel biology.
Of course, despite this early evidence, it’d be definitely exaggerating to suggest that Octo-VC can perfectly capture distribution of all possible tumor responses. Foundation models are not magic! Having mostly observational data could very well lead the model to predict something is causal when it is only associative. There are ways to get models to better learn the ‘rules’ of the system rather than the ‘outcomes’ of the system — the former of which generalizes beyond the immediate training data — but even fields beyond biology are still figuring out the best ways to do that.
But the utility of models like Octo-VC will almost certainly not in being 100% correct, or even 75% correct, but in offering directional hypotheses where none previously existed. This is something that is very hard to benchmark! Unlike domains like protein folding, where you could assemble together a decent approximation of physical truth, the systems-level dynamics of real tumors in real patients are messy, multivariate, and context-dependent in a way that almost certainly resists clean formalisms. Models like Octo-VC will not generate these clean formalisms, at least not for a very long time.
But it will almost certainly help immunologists ideate far faster than they previously may have, allow clinical trial stratification decisions to be made with more supporting evidence, and strengthen conviction for whether a certain drug should be licensed. We are a long way off from curing cancer, but Noetik is quite close to the ‘metal’ of raw clinical utility than I could’ve appreciated prior to starting. This shows up both in terms of the culture (lots of ex-Genentech people!) and the priorities of ongoing projects.
Today, amongst other things, Noetik is thinking a lot about mechanistic interpretability, better masking strategies, how natural-language LLM’s can help with this work, curriculum learning, writing the largely unwritten rules for spatial tumor biology, understanding where our models hold the most promise for partnering with pharma companies, and deciding which licensable drugs we think we understand ideal patient cohorts for. Lots of things on the roadmap! And I’m very excited to be a part of it. If any of this sounds interesting, again, feel free to reach out to abhishaike.mahajan@noetik.ai or DM me on X!
Finally, I still plan to continue writing independently here at owlposting.com, and I have 4 articles already written + ready to release, along with a podcast I filmed during my recent stay in San Francisco. The future is bright!
Before joining, I didn’t quite appreciate how insane whole spatial transcriptomics is as a data modality. I’d like to write an essay covering this particular type of data someday, it’s really quite extraordinary how little we understand about spatial biology, and how much insight this gives us into it. Yes, the connection from RNA to protein hovers at around 40%-60%, but you can still learn an awful lot of interesting information from it!
On the point of data quality over quantity — if the end goal is to make patient-level predictions (e.g., response to therapy), won’t we eventually need large-scale data (10-100k+ patients even)? High-dimensional, multi-modal data per patient is crucial, but with few patients, the analysis risks becoming more descriptive than predictive. That’s still great for hypothesis generation but maybe not for ML. One analogy is models that predict sex from retinal images where the signal is real and non-obvious, but only becomes robust and generalizable with scale.
I think there's an opportunity to combine quantity and quality. In endoscopy, we're finding that we can use massive quantities of unlabeled data to train a self-supervised encoder. That encoder allows us to train downstream application decoders with relatively small datasets that are well-curated and labeled. The example we've shown so far is that we can take the placebo arm of a Ph3 ulcerative colitis trial that's 300 patients and classify the responders vs. non-responders from only their baseline colonoscopy video!