


This post is co-written with Tobias Schraink, a former colleague at Dyno Therapeutics. He’s exceptionally talented at computational biology, building up data pipelines, and answering questions about biology from curious people (me). Incidentally, he’s job hunting! DM him on Twitter or Linkedin if his profile seems interesting!
Introduction
ESM3 dropped a few days back, along with the announcement of its parent company, Evolutionary Scale. Besides the typical metrics, they included one other curious benchmark for success: creating an evolutionarily distinct version of GFP, or green fluorescent protein. This new protein, roughly 100 mutations away from wild-type GFP, was deemed ‘esmGFP’.
This isn’t an alien benchmark. Profluent also did something similar, flexing their recent model by using it create a Cas9-like protein, which was 400 mutations away from the wildtype version of it. As with Profluent’s redesign, the true accomplishment of ESM3 has marginally little to do with the GFP redesign, it’s just a means to demonstrate the power of the model.
Prior to reading the paper, I had only somewhat heard of GFP via its use in protein reporting and usage in glowing rats (which, as it turns out, isn’t GFP, but some other less immune-stimulating fluorescent protein). After some reading, I thought a quick rundown on GFPs and this new esmGFP might be interesting!
That said, I'm keeping this much shorter than my usual primer posts. It’s GFP — there's only so much to say!
What is GFP?
It’s a 238 amino acid, structured protein that lights up green (hence the name) when you shine specific types of light on it. First discovered in jellyfish, it has, over the course of 70~ years, become one of the most widely used tools in molecular biology.
The best way to give an overview of it is via an FAQ, so let’s do that.
How does it shrine green? GFP is shaped like a barrel that loops in on itself. Within the barrel, specifically on the aforementioned loop, there are amino acids (Ser-Tyr-Gly) that, together, form a ‘chromophore’, which just refers to molecules that can absorb wavelengths of light. Upon blue, violet, or UV light hitting the chromophore region, electrons in it will excite, and slowly return back to their baseline state. The ‘return to relaxation’ happens to release green light.
Here’s the structure of it; the chromophore (which, remember, is part of GFP, not separate!) lies in the middle of the barrel. Funnily, the best structure I could find also came from an ML GFP mutation paper!
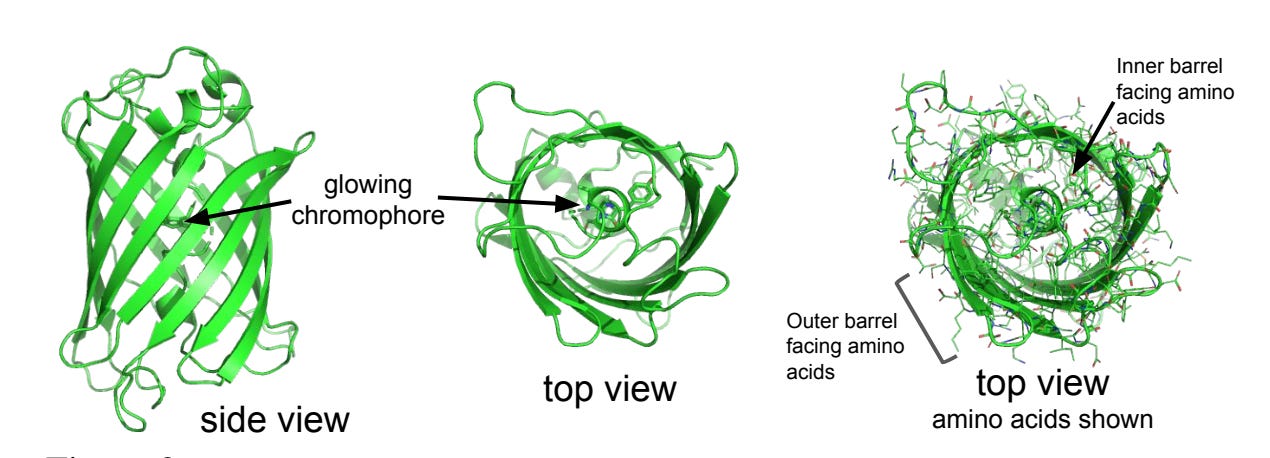
Why green? And why can only blue/violet/UV light be used to make it light up? The difference in energy between the excited state and the ground state of the GFP chromophore electrons corresponds to green light wavelengths (around 510 nm). As for the latter question, blue/violet/UV light similarly correspond to wavelengths that are high-energy enough for the GFP chromophore to be excited. You can shine a red light onto a GFP; it’ll just not do anything because the electrons are not sufficiently excited for there to be a ‘relaxation’ phase. To note, there are other non-GFP proteins that can emit alternative colors, such as RFP’s, or Red Fluorescent Proteins! These are largely structurally identical to GFP’s, but have sequence mutations on the chromophore + barrel regions that modify the difference in electron excited-ground states on the chromophore.

What makes GFP unique? Lots of things in the world are chromophores. But GFP has become a near-staple in lab research for three main reasons. We’ll get into why these are such useful characteristics in the next question.
Bright. GFP lights up very green when it's excited, and only requires external light to do so. Conversely, many other chromophores have relatively weak excitation and are, thus, hard to monitor by an external entity (usually a human with a microscope). Many other chromophores also require external assistance to form a chromophore, such as added proteins, whereas GFP mostly works out of the box (given access to oxygen).
Stable. GFP doesn’t really unfold, its barrel-shaped structure is quite stable in a variety of environments. More importantly, the chromophore within a GFP is not easily ‘quenched’ by outside interference (say, other proteins). From a structural perspective, this is because the hydrophobic barrel shape of GFP protects the chromophore from having to interact with much of the environment. This is ideal from a utility perspective; GFP needn’t be ‘babied’ to ensure that it’ll still be capable of lighting up when surrounded by other molecules. As with all claims about the stability proteins, this isn’t always true. It’s a decent-sized large protein with a complex structure, sometimes things will go wrong! But even this was largely solved through protein engineering using only two simple mutations, a testament to how stable base GFP already is.
Innocuous. GFP isn’t reactive with much. As such, it doesn’t alter the usual behaviors of cells, proteins, and the like from it existing alongside them. The same addendums as in the ‘Stable’ section above apply; there are exceptions, but still relatively minor and solved with a small set of mutations.
What do people use GFP for? Because of its brightness, stability, and innocuous nature, GFP has become extremely popular as a detection method of protein tags. One application involves splicing the sequence for GFP at the end or the start of a protein-coding gene, such that when the gene is transcribed, GFP is tagged onto the structure as well! This allows for a researcher to have an easy way to track the location of the protein as it’s shuttled around the cell, purely by shining a light onto a cell and seeing the green spot (GFP-tagged protein) move around. And, because GFP is stable and non-reactive, it doesn’t (usually) affect the usual function of the protein either. There are other use-cases as well, such as detecting when a certain section of a genome is being transcribed or when an engineered virus has transduced a cell.
All in all, it’s a really simple protein with a wide array of use cases.
ESM3 redesigned it. How? Why? We’ll get into that!
What is esmGFP?
esmGFP is largely equivalent to GFP, just roughly 100~ mutations away from it.
This alone doesn’t make esmGFP “better” than GFP. Proteins many mutations away from wild-type are interesting in some cases, especially viruses, but definitely not with GFP. Moreover, unlike Profluent’s Cas9 redesign, which potentially allows them to escape patent laws over its use in therapeutics, GFP is basically perfect as is. Some things could certainly be improved about GFP, such as its dependence on certain acidity conditions, inability to be tacked onto certain proteins, and its requirement for oxygen to function correctly. But, for the most part, it works fine. Even if we did desire to heavily mutate GFP to improve its performance, not many mutations are necessary to do that, e.g. only 10 mutations are necessary to improve fluorescence intensity by 3.3x.
The only reason one would redesign GFP is that it is hard to do so.
And that’s exactly why ESM3 tackled the problem! From the paper:
…Rational design and machine learning-assisted highthroughput screening have yielded GFP sequences with improved properties—such as higher brightness or stability, or differently colored variants—that incorporated small numbers of mutations (typically 5 to 15, out of the total 238 amino acid coding sequence) from the originating sequence.
Generating a new GFP would require materialization of the complex biochemistry and physics that underlie its fluorescence…Light emission is highly sensitive to the local electronic environment of the chromophore. For these reasons, obtaining a new functional GFP would require precise configuration of both the active site and the surrounding long range tertiary interactions throughout the beta barrel.
This sets up the problem quite well. While the Cas9 protein does have a fair bit of monomeric competition in the ‘what else can cleave genetic material?’ dimension — all of them with fair structural differences — GFP is a bit more standard. Typical methods to mutate it to yield different properties are usually quite minor, only in the realm of 5-15 amino acids. Generating a structurally equivalent but sequence-wise unique GFP is extremely novel and, if we’re to take the paper at face value, very challenging.
How did they do this? We’ll avoid a lot of the minutiae of the ESM3 architecture setup here, and just view it as a conditional generational model, where the conditions can be structure, sequence, and/or function.
ESM3 conditions the design process on a provided set of 6 amino acids (Thr62, Thr65, Tyr66, Gly67, Arg96, Glu222) sequence/structure + the structure (but not sequence) of residues 58-71, all of which corresponding to chromophore/chromophore adjacent positions that in the normal GFP of residues. From the paper:

This may be viewed as cheating, since you’ve already provided the ‘light emitting’ part of the structure, but this region also seems to be pretty tolerant of mutations anyway. I stumbled across a paper that analyzes the fitness landscape of the chromophore region (very similar to the above 6 amino acids) and find that the overwhelming majority of mutations still allow fluorescence (though negatively affects overall performance). Conversely, the well structured barrel section of GFP seems ‘harder’ to re-design, as it has a hard-to-tease apart impact on the structure of the chromophore, but I’m also not finding many papers on the subject and am not a protein designer so ¯\_(ツ)_/¯.
What was the design process? A bit involved, relying on two rounds of generation. The first created tens of thousands of designs in-silico, were filtered down to 88, and all expressed in-vitro. One of these were picked as a GFP-like seed (referred to as B8) which was 96 mutations away from WT. This one then went through another iterative in-silico design process, filtered down, and re-expressed. One of these final re-expressions, also referred to as C10, was deigned esmGFP, a further 15 mutations away from B8.
Of particular interest are the filters that were used during the design process. Specifically, three filters relied on having access to crystallized GFP structures (1QY3 and 1EMA)! This isn’t a bad thing exactly, but it does perhaps inflate the utility of the model for proteins that lack a crystallized structure. The GFP design process may have been more convincing had it relied on AF2/ESMFold/ESM3 predicted structures instead — though it is likely that those have memorized GFP entirely. This is an extremely minor point overall, especially given that these filters are specific to the region of the chromophore we provided to the model.
Either way, here are the crystal-structure-reliant-filters.

How well did esmGFP perform? On par with GFP on a few metrics, but distinctly different in one category.
Let’s start with how it equaled GFP in performance. The below chart shows that the excitation (Ex)1 spectra of EGFP (a form of GFP usually used in lab) matches that of esmGFP; blue/violet, higher energy. The same could be said of the emission spectra2, which peaks at green. Everything is as expected!

This next chart is a bit more interesting. The fluorescence of esmGFP, B8, and ‘knockouts’ (esmGFP with known loss-of-function mutations on the chromophore) were compared to a few control GFP’s that are regularly used in the lab: avGFP, cgreGFP, and ppluGFP. As expected, the knockouts barely lit up, the controls did fine, and esmGFP was better (brighter) than B8.
But, more curiously, both B8 and esmGFP took longer than a day to fully mature to their ‘peak’ fluorescence, up to a week! This phenomenon wasn’t something I was even previously aware of; I assume GFP’s are born with a fully functioning chromophore, but it turns out interaction with oxygen molecules allow a chromophore to fold into the correct position.

But the amount of time esmGFP takes to mature is strange even amongst most GFP’s; most other ones that are actively used have maturation times measured in tens of minutes, not days!

This isn’t a huge knock against ESM3, there is immense accomplishment in being able to design a protein with such specific functionality, massively far away in sequence space from wild-type, all with comparable fitness outside of one dimension (maturation time). Still though…what caused such a long maturation time? Would love to hear a structural biologists take on this!
Anything else interesting? Two things!
One, the paper claims 58% sequence divergence from esmGFP to any other GFP protein. Assuming a constant rate of mutation amongst GFP’s, this is where the ‘500 million years of evolution’ part of the ESM3 paper title comes from.
But what about divergence to any protein?
Brian Naughton, who famously (in a very specific niche corner of Twitter) found that the Profluent Cas9 redesign could be 98% recapitulated by three Streptococcus sequences, performed the same analysis here with esmGFP! It’s not as severe as an overlap, but still, some! Here is the original post:
Two, esmGFP is generated with ESM3 7B, not ESM3 98B! This is surprising, given that 98B had generally superior performance on every benchmark throughout the paper. I suspect the reason for this is more logistical than scientific. Wet lab experiments take time, a 98B model likely takes forever to train, and with Alphafold3 released just a month ago, Evolutionary Scale likely just wanted to get something out. Excited to see follow-up work on what 98B is capable of in a design setting!
Conclusion
esmGFP isn't groundbreaking on its own, but that's not really the point. It's more of a proof of concept for the model behind it. What's actually impressive is the all-in-one approach that ESM3 took — combining structure, sequence, and function in a model with 98 billion parameters. And Evolutionary Scale did this with only about 15 employees, which is insane! The clinical and research impact remains to be seen, but there's definite potential here for massively speeding up existing workflows.
I’m very curious where Evolutionary Scale goes with this. It seems like they are eschewing the therapeutic route, going with a more model-as-a-service setup. This is interesting and, for the most part, unprecedented in biology! The Schrödinger model may be a close parallel to what happens; a hefty license fee for use amongst a department. But perhaps a different story will be told. While Schrödinger had plenty of open-sourced competitors to their tools, ESM3 98B stands largely alone alongside Alphafold3, potentially allowing them to price their tools in entirely different ways. If useful enough, potentially even a royalty of drugs that were created with ESM3 in the loop? This seems like the only way the company could afford to continue training models of this size and deploy them — Schrödinger-level economics probably won’t cut it. But the time spans before drug royalties kick in are long — multiple years — and it is unlikely that ESM3 is currently pivotally important enough to justify such a high price. But ESM4? Who knows? I can definitely see tools like this becoming such an integral part to faster drug development that biotech companies would be willing to cut into their own share of the profits to have access to it.
Either way, very curious as to what the typical heroes of proteomics ML open source — Baker, AlQuraishi, and Ovchinnikov — do next, given the move by both Evolutionary Scale and Isomorphic to be largely closed-source.
Finally, if there do happen to be any Evolutionary Scale engineers or scientists reading, I’m plugging my article here if ESM4 has yet to start training and ideation is still on the table:

MD is the next frontier of interesting training tokens!
Thank you for reading this post! Every two weeks, I’ll be posting something about biology, ML, or the intersection of the two. If this interests you, please subscribe!
Referring to the wavelength of light the chromophore is absorbing.
Referring to the wavelength of light the chromophore is emitting.
Great post as always! Keep up the good work.
Well, I am not a structural biologist, but at one point many years ago I was reasonably well-read on applied GFP biochemistry. I think the reason for the long maturation time could either be (a) slower folding of the expressed protein to the correct beta barrel structure, which seems unlikely, or (b) slow maturation of the chromophore, which seems far more likely. The chromophore maturation is nicely explained by the page you linked to and consists of three steps: (i) "torsional rearrangement", (ii) a cross-chain chemical reaction to form a ring and further stabilize the folded structure, and (iii) reaction of the ring with molecular oxygen to form the extended conjugation required for fluorescence. The "superfolder" GFP variant (sfGFP in your table) seems to accelerate steps 1 and 2. Don't know why esmGFP is slow...my guess is either steps (i) or (ii) are slower, but although I think it's less likely it would be really cool if it were step (iii). (Accidentally creating a protein less permeable to dissolved oxygen gas would be sweet.) Also I found this paper on the folding mechanism of GFP pretty good https://www.sciencedirect.com/science/article/abs/pii/S0022283607010509