


There is surprisingly little written on the scaling laws displayed in current protein language models (pLM's); there is still no compute-optimal paper in the protein world. Doing anything even mildly similar to the Chinchilla paper would take me forever, so I'll do something much more basic: assembling the token:parameter number of several well-known pLMs together.
To simplify things, I'm going to use this papers calculation of the average sequence length of UniRef50, which is 325, so each datapoint has 325 tokens. This will lead to inflated token numbers for BFD30, since those are largely small metagenomic proteins, but that's fine.
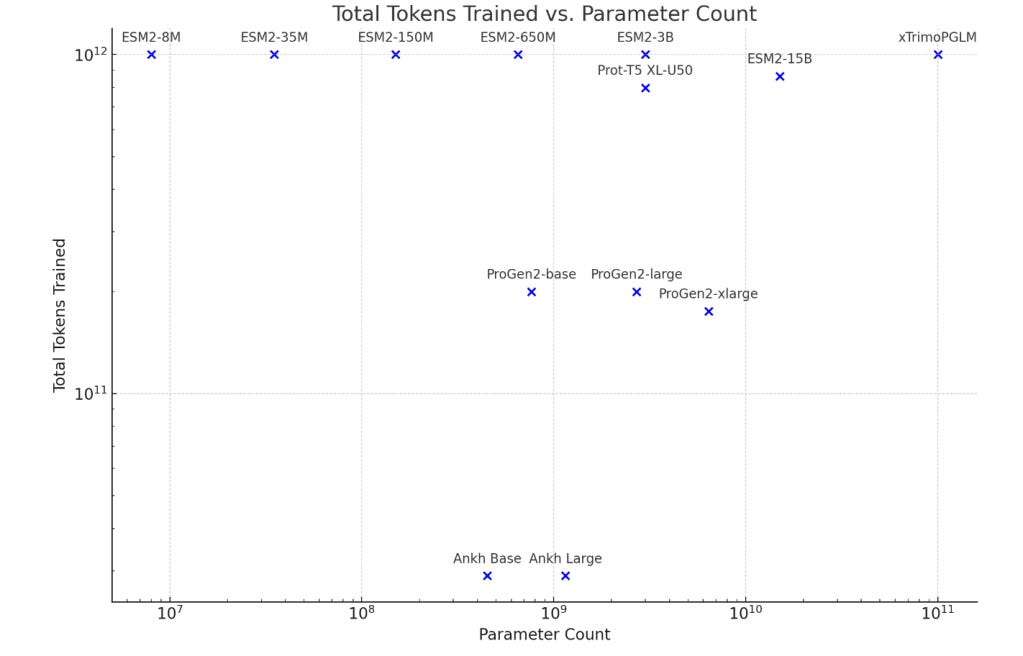
Curious!
What does the sweetspot for tokens:parameters look like anyway? For NLP, it's ~20 tokens per 1 parameter.
And the ratios for the protein language models:
Interestingly, ProGen2-xlarge is the closest model that is 'optimal' from NLP standards, but xTrimoPGLM claims to be better than it in many domains! They do comment on this in the paper:
We observed that large-scale models are more sample efficient, reaching these perplexity levels with substantially less training data: less than 500 million tokens to match ESM2 trained on 1 trillion tokens, and less than 150 billion tokens to parallel ProGen2-xlarge trained with 350 billion tokens, even if the learning rate schedule has not yet ended, resulting in an overestimated loss value at this stage.
That's largely all the work here I'm going to be doing, just a few final comments:
ProGen2 could be worse compared to xTrimoPGLM due to a much smaller dataset size (protein diversity matters!) and may have nothing to do with optimal training.
It could be the case that xTrimoPGLM is massively undertrained, the paper gave no proof that the training they have currently done fully exploits the underlying dataset or parameter count-size.
The largest of these models are almost certainly going to end up being a novelty for the time being, while xTrimoPGLM is SoTA, it is SoTA in the same '.5% bump on CIFAR' way that lots of papers were in the late 2010's; an interesting paper, but not paramount for protein designers to use. Things could always change overnight though...
Very interesting to see that ESM-15B may (potentially) be missing enough parameters to take full advantage of its dataset! Most people, including me, has assumed 15B was far too many parameters given the very mild bump over 3B/650M. It'd be extraordinarily expensive to explode up the layer size of ESM-15B to 30B to see if there are any jumps in accuracy, but a fun experiment if anybody has a few 100k~ lying around.